科学软件部署困局:一套机制如何将成功率从60%提升至95%以上
2021年,我第一次尝试在实验室服务器上复现一篇Nature论文的代码。README文档写得很漂亮,依赖列表看似完整。然而从编译到运行,我整整折腾了11天。
困局:从“发布即存在”到“运行即事实”
这不是个例。GitHub上超过80%的科学软件仓库,在克隆后无法直接运行。依赖缺失、版本冲突、系统不兼容——这些问题消耗了研究者大量宝贵时间,却从未被系统性解决。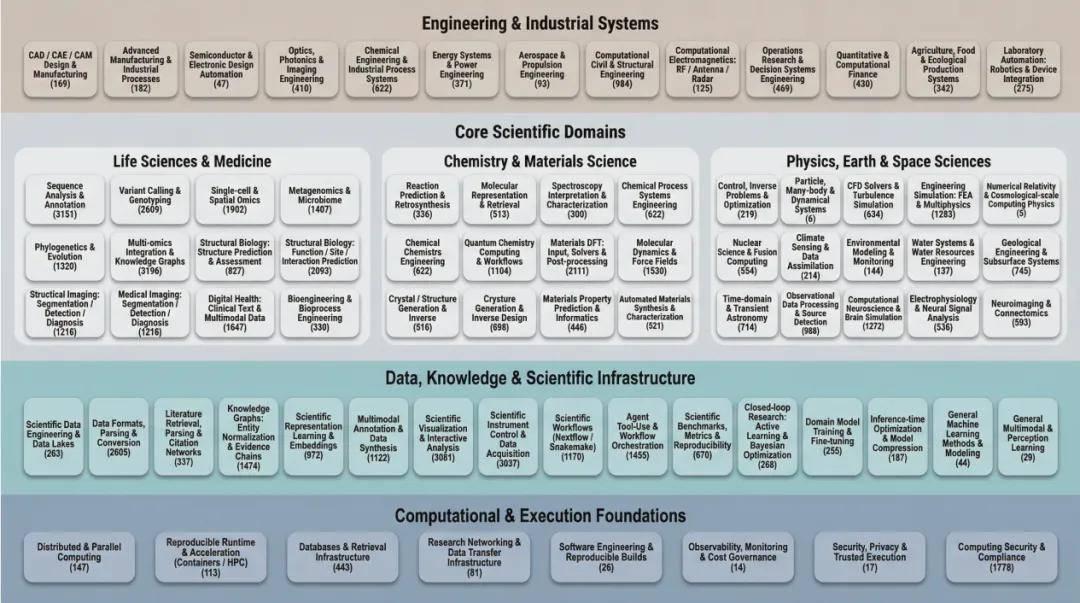
更深层的矛盾在于:AIforScience的崛起让这一问题从“效率问题”升级为“第一性问题”。AIAgent需要真正能执行的工具,而非假设中的能力。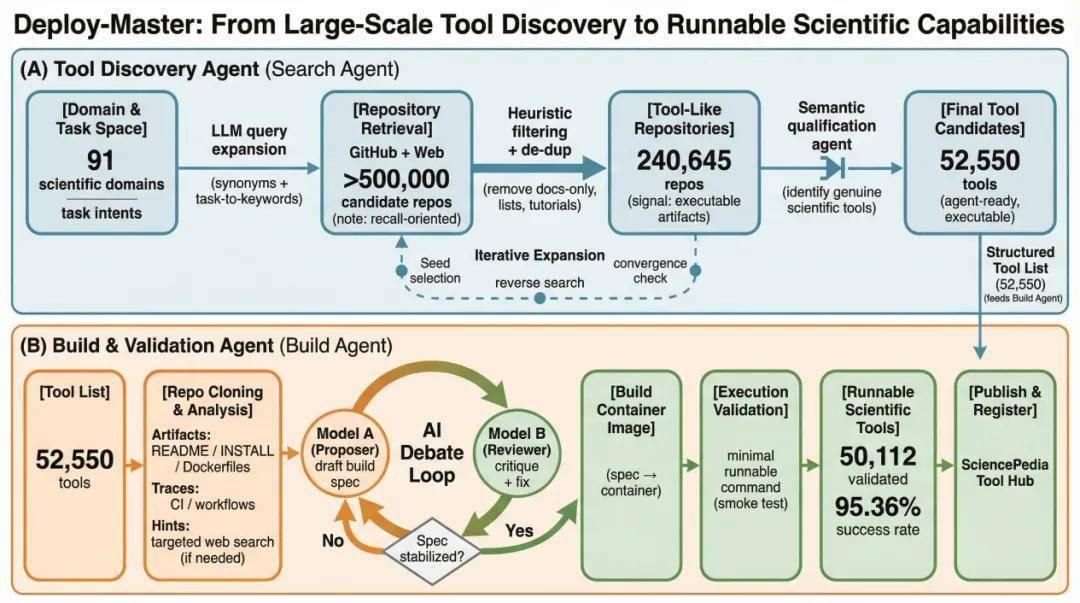
破局:Deploy-Master的链路化设计
Deploy-Master没有试图在单个环节突破,而是将部署重构为一条完整链路:发现→理解→构建→验证。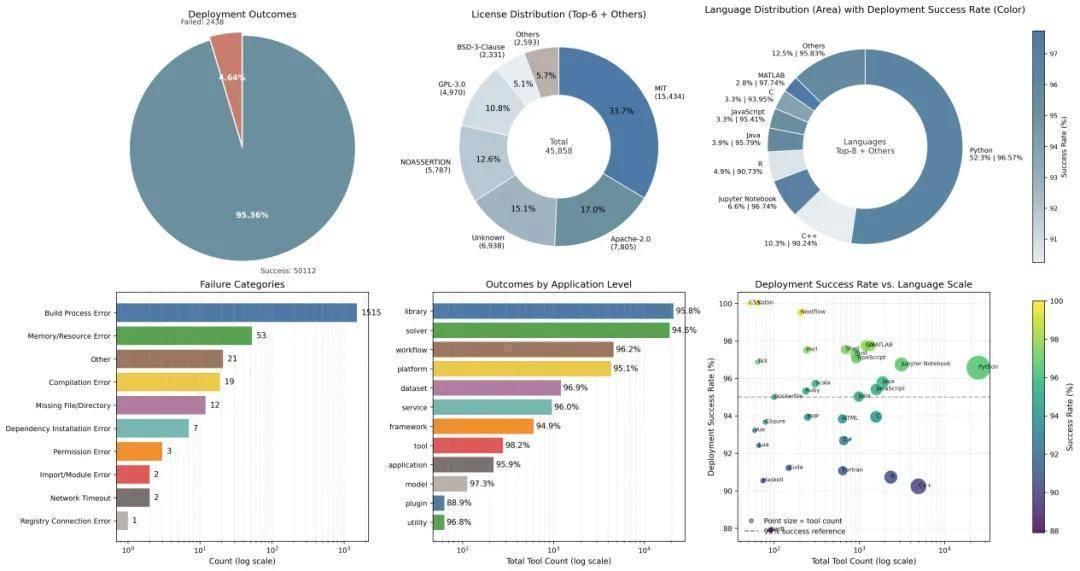
SearchAgent从91个科学与工程领域出发,通过锚点扩展策略将50万仓库收敛至52550个候选。这一步的价值不仅是筛选,更是对科学工具世界边界的首次结构化刻画。
核心:双模型辩论机制
单一模型生成构建规格的成功率仅有50%-60%。根因在于:科学软件的构建信息充满隐含假设,这些假设从未被显式表达。
Deploy-Master引入双模型博弈:BuildAgent生成方案,ReviewAgent独立审查并主动寻找不一致、缺失依赖与环境假设。多轮迭代后,方案趋于稳定。这一机制将成功率提升至95%以上。
验证:170种语言、50112个工具
在已部署的50112个工具中,我们观察到:构建时间呈长尾分布,Python占比最高,C/C++和Fortran因编译链复杂导致成功率略低。失败原因高度集中于构建流程错误,而非资源或权限问题。
这说明:失败不是异常,而是系统暴露问题的信号,也是自我修正的契机。
结论:执行是AgenticScience的前提
如果科学软件这一“最难部署场景”能够被系统性解决,那么问题本质便已清晰:不是工具类型差异,而是是否建立了以执行为核心的基础设施。
Deploy-Master证明:当“工具能否运行”从默认假设变为可验证事实,科学智能体才真正拥有了与现实世界交互的基础。